If there’s one thing we need to know more about in today’s world, it’s the minutiae of celebrities’ daily lives. As I’ve passed these months in quarantine, my mind always seems to drift to serious matters like what Chris Evans had for breakfast and whether Dwayne “the Rock” Johnson is still as yoked as he was in F8 of the Furious. The amount of time spent wondering is unhealthy but worse yet, I know I lack the strength to kick the habit.
To quell my wandering thoughts, I’ve begun to build a significant news detector that alerts me when something “notable” in the world of celebrities occurs. Every 10 minutes, it looks at a couple of the most prominent celebrity gossip websites, reads the latest content and pings me when it thinks its read a significant news item.
People differ on their go to source of celebrity gossip. I, for one, mainline TMZ and Just Jared so the analysis that follows draws from the former’s articles. I scrapped the entire history of TMZ articles (>100k articles) and used Twitter’s API to gather all of TMZ’s tweets. I merged these two datasets based on the common urls and set to building a model that used the article’s text to predict the number of retweets. I defined any article that received more than the 75th percentile number of tweets in the past 30 days as a significant article (everything else was insignificant). With the data cleaned and rearing to go, I trained a deep learning model (BERT) on less recent data and tested it on the most recent data (after all in practice, we would be trying to predict future significance).
So how did it do? The model was able to notch an overall accuracy of 70%. Good, but not great. If we dig deeper, we see that the model is better at identifying the insignificant news and not as good at identifying the juicy stuff.

Let’s put some actual articles to the test. The table below shows the headline, actual significance (as defined above) and our prediction of significance for the most recent 20 news items in the data set.
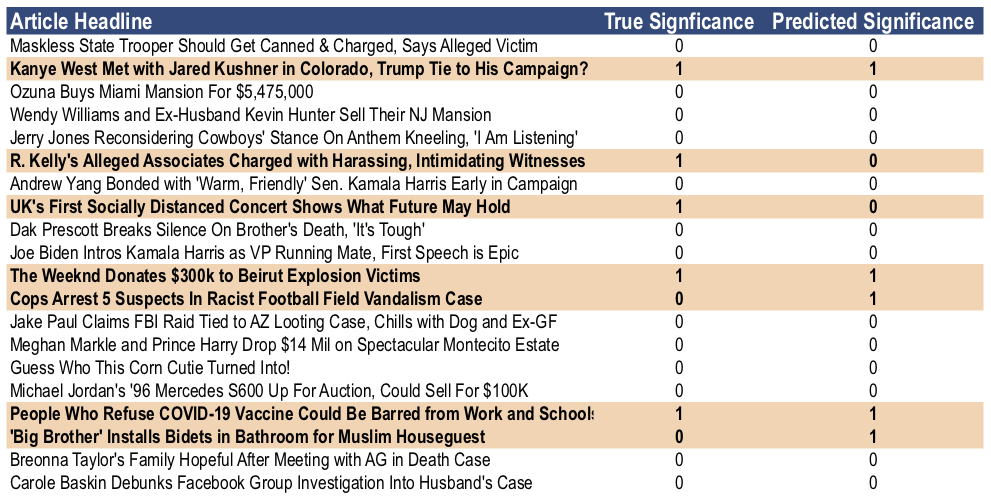
If these last 20 news items are an indication of future performance, I’m comfortable missing out on stories like Wendy Williams and her ex selling their NJ mansion (I do have an inkling to know who that ‘corn cutie’ turned into though). As mentioned previously, the model will do quite a good job at filtering out the superfluous junk. What it labels as significant however, isn’t always on the money. As seen above, the model would have directed me to read the bidet tidbit which I can’t imagine is breaking news.
(An inquisitive pair of eyes may have noticed that the Kamala Harris VP story didn’t register as significant both in actuality and in our model. While it may be a very significant event in the real world, this is a gossip site and non-salacious political stories aren’t as sure to move the needle.)
Further Improvements
The results here are encouraging but by no means is our work done. There are several potential improvements I’ve identified.
Rather than framing news as a binary significant and insignificant classification problem based on my arbitrary cutoff, we may see more useful results by trying to predict the precise number of retweets. Additionally, a more thorough cleaning of the text would probably go a long way (this initial run used very little preprocessing).
Final Thoughts
I can’t say I won’t peak at TMZ from time to time but this has at least gotten me closer towards keeping me informed but not too informed.
All code can be found here.
