
The Gist
To kick things off, we thought it would be both informative and interesting to explore how machine learning can help deduce personality traits and types from text data.
There is no shortage of tests and literature out there already on personalities. From the Big 5 to the 16 traits of the Myers-Briggs Personality types to the random ones that appear as ads on one of your feeds, for some reason discovering membership in a personality type is both alluring and dignifying.
There’s no doubt in our minds that people exhibit varying degrees of different personality traits and whether a person falls wholly into one personality type or another is not a question we intend on shedding any light on. Instead, the hypothesis we aim to test is that a model can classify predetermined personality types based on text data.
Introverts & Extroverts
The labels introvert and extrovert get tossed around a lot. Sometimes they’re applied correctly; other times, they’re used mistakenly to talk about one’s degree of shyness. The difference is a bit more nuanced. A few years ago, Susan Cain wrote a well-received book on introversion, Quiet: The Power of Introverts in a World that Can’t Stop Talking. In addition to going into great detail on the nature of introverts, the book does a great job of showing the true distinction between introverts and extroverts.
Using this as a jumping off point, since the distinction between the two groups is tricky, useful data could be hard to come by. If we take a step back though, we would imagine that in aggregate self-identified introverts and extroverts more often than not correctly identify themselves. Now, let’s imagine a very plausible reality where communities of these individuals wrote about themselves and how they felt during different situations. Presumably, this data would be extremely informative of understanding the core attributes of each community. Enter Reddit.
Our data set hails from subreddits that cater to each group (r/introvert and r/extroverts). Members of these groups make our life easy by posting in great detail how they feel during various situations. We chose to use the content of these posts (and excluded the comments) as inputs into our classification model. We acquired out data using the helpful python library, praw. In one pass, we were able to get roughly 4,000 clean posts in total from these two subreddits. (In further work, we’d definitely want to expand the size of this data set.)
With our data processed (using term frequency inverse document frequency) and rearing to be analyzed, we were faced with the critical decision of which model to employ. We chose to use logistic regression as our benchmark and a support vector machine (SVM) for comparison. (Were our data set larger, we would have tested deep learning methods as well.)
Our benchmark model is able to achieve 87.1% accuracy which is quite good but pales in comparison to the SVM which notches 97.0% accuracy!

So how should we interpret this? While 97.0% is nothing to scoff at, we should remember that the content of these posts are inherently more full of introverted or extroverted language than we’d find in standard texts. So if we were to feed our model someone’s words as they spoke, the model would likely fail, unless these words were directly related to behaviors common of introverts or extroverts. Similarly, most pieces of writing you’d find in a news article aren’t going to go on at length about being socially drained and needing to recharge. In that sense, the model is limited to not being transferable to other domains. On the other hand, it’s extremely impressive that a relatively simple model can distinguish introverts from extroverts.
Myers-Briggs Personality Types
We could leave things here but where’s the fun in not exploring more. Instead of formulating our problem as a binary classification between introverts and extroverts, let’s see what happens if we create a multiclass model of the 16 Myer’s Briggs Personality Types. Rather than using the two subreddits mentioned above, we’ll use posts from the subreddit of each of the personality types. Thankfully, we’re blessed with more data here (~40,000 observations).
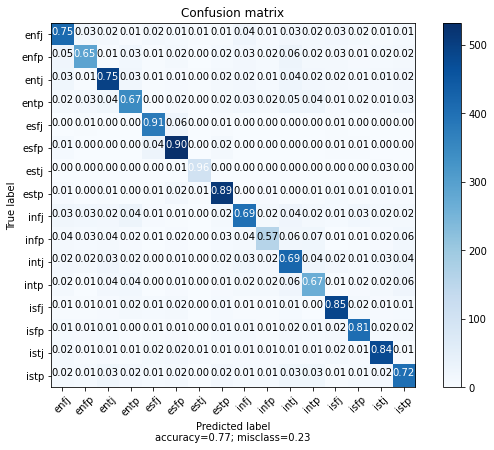
Feeding this data into the same models, our support vector machine is able to achieve an F1-score of .77 after tuning the model’s hyperparameters. (The benchmark only achieves a 0.67 F1-score.) This is less than our previous binary problem but still impressive in our minds because the difference between the different types is far more nuanced here. In the confusion matrix below, we can see how well the model did in classifying each of the 16 types.
For those interested in reproducing this work or expanding on it, follow the link to our GitHub here.
A Note on Data Cleaning
We chose to leave in the words extrovert and introvert as well as the various personality types because while one might think it would be a way for the model to cheat in classification, there’s reason to believe that if someone were to specify one of these words, they may be using it in the context of a comparison as opposed to self-identification.
